

Real-time video analytics revolutionizes decision-making through immediate processing of live video data, providing transformative insights across sectors like security, retail, manufacturing, and sports. However, the translation of cutting-edge video analytics models into practical applications poses significant challenges. Our exploration delves into the intricate world of constructing real-time video analytics applications, where the convergence of machine learning and streaming technologies injects intelligence into live streams.
In the subsequent sections, we navigate through the essential components and considerations when designing and implementing real-time video analytics systems. From understanding the fundamentals of streaming technologies to delving into the nuanced decision-making processes of choosing between edge and cloud computing, we systematically unravel the layers that form a robust and intelligent video analytics solution.
To illustrate the practical application of these principles, we present a compelling case study that explores the construction of an intelligent athlete tracking and action recognition system on live sports streams. Finally, we discuss our thoughts on how AI is reshaping the video streaming landscape.
Streaming Explained
Envision a typical day in 2024. You start your workday by joining a Zoom meeting, connecting with coworkers halfway across the country. Later you tune in to the keynote talk at the online conference you’ve been attending. Perhaps you get a notification from your doorbell camera that a package was delivered to your door. As evening approaches you decide to catch the last few minutes of the Bulls game on your tablet while you cook.
Live video streaming has seamlessly integrated into our daily routines across a spectrum of applications. Although diverse in their specific implementations, each application, whether peer-to-peer streaming in web conferencing or one-to-many streaming in major sporting events, shares a common goal: delivering video content from its source to the end-user’s device. Despite variations in construction, the underlying architecture uniformly addresses the fundamental challenge of ensuring efficient video content delivery.
In practice, delivering live video over the internet follows the same core pipeline:
Contribution
Often called “the first mile,” the initial stage of the pipeline ensures video content is contributed or uploaded from its source. This can originate from various devices, such as IP cameras typical in retail and security applications, or live broadcast equipment used in sporting events. The contribution phase encodes the raw video content using protocols like RTMP, RTSP, SRT, or WebRTC to ensure efficient transmission.
Processing and Distribution
Once the live video is contributed, it enters the processing and distribution phase. Here, the video content undergoes necessary encoding, transcoding, and other processing tasks to optimize it for efficient delivery. The processed content is then distributed to servers strategically placed to handle incoming requests. Depending on the application’s scale and demands, Content Delivery Networks (CDNs) may be employed to enhance distribution capabilities.
Delivery
The final stage of the pipeline, sometimes referred to as “the last mile,” involves delivering the processed video content to end-users’ devices. This includes efficient streaming to accommodate real-time viewing, minimizing latency and ensuring a smooth playback experience. Depending on the application type, scale, and latency requirements different delivery protocols like HLS, MPEG-DASH, or WebRTC may be used.
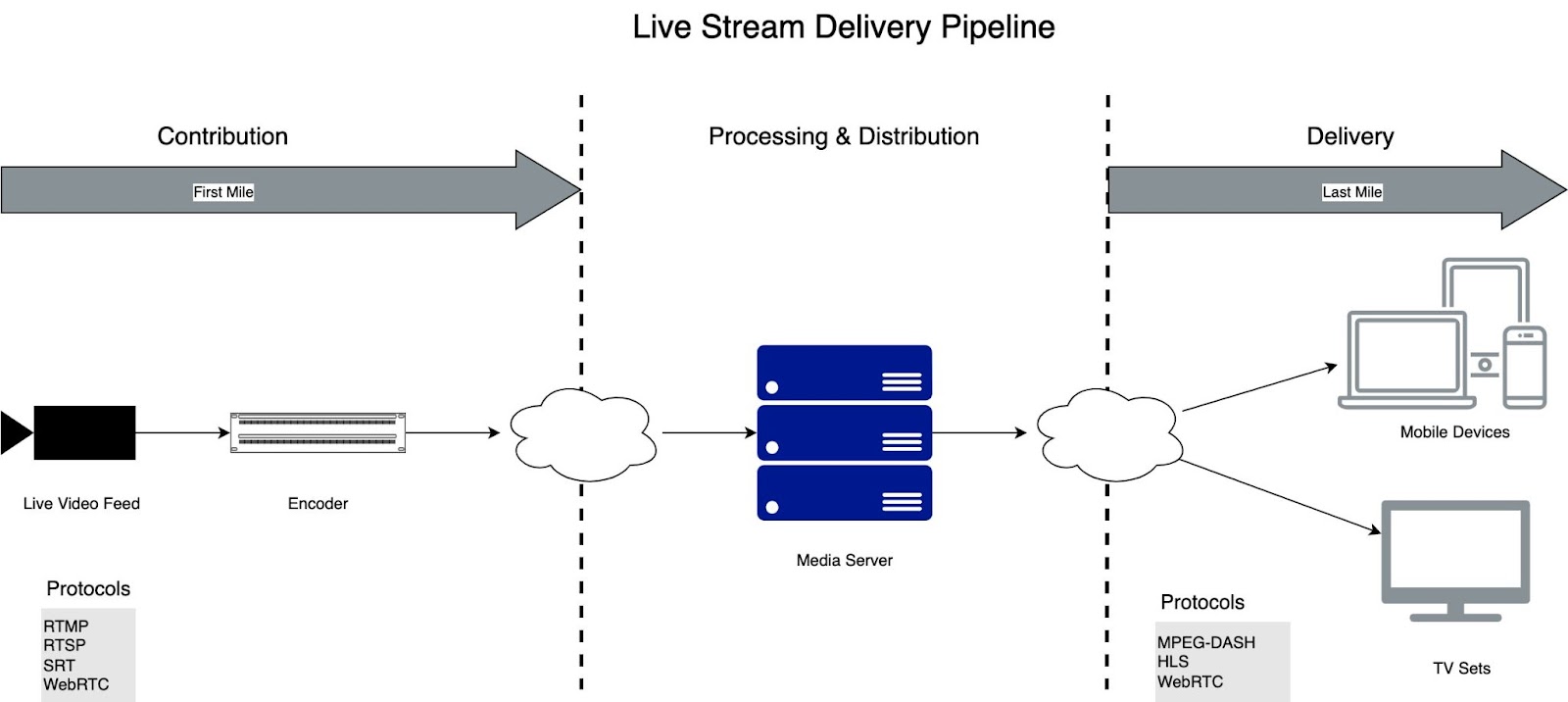
The choice of protocol in either contribution or delivery phase is highly dependent on the application. When building a real-time video analytics application it’s critical to understand the benefits and limitations of each. As we dive into the most common protocols, we’ll see that latency isn’t necessarily the major driver in every application.

Real-Time Streaming Protocol (RTSP)
RTSP is a versatile protocol designed to control audio/video transmission between two endpoints, enabling low-latency transport of streaming content over the internet. While once dominant alongside RTMP, RTSP is now primarily used in surveillance, CCTV, and as the protocol of choice for IP cameras due to its simplicity. Operating at the application layer, it commands streaming media servers through pause/play functions, relying on RTP and RTCP for data movement. With wide support for audio and video codes, RTSP offers the benefits of low-latency and widespread use in IP cameras, albeit with limitations in playback support and scalability often requiring transmuxing. As such, RTSP is usually used in the first-mile contribution from IP cameras and is subsequently repackaged for last-mile delivery and playback.
Real-Time Messaging Protocol (RTMP)
RTMP, a cornerstone in the early days of streaming, operates as a TCP-based protocol with a focus on maintaining persistent, low-latency connections for a smooth streaming experience. Once the core technology behind Adobe Flash Player, RTMP retains widespread support among encoders and media servers. However, it faces challenges in playback on modern browsers and devices, limiting its compatibility. Despite its diminished role in last-mile delivery, RTMP remains a popular choice for content contribution in the first-mile workflow. Similar to RTSP, RTMP streams are transcoded to adaptive formats like HLS or DASH for efficient and scalable last-mile delivery.
Web Real-Time Communication (WebRTC)
WebRTC is not a single protocol but a fusion of standards, protocols, and JavaScript APIs. It stands as a pivotal technology for interactive live streaming. With its native browser support, it eliminates the need for external applications or plugins. Its super low-latency and browser-based nature make it ideal for applications demanding near-real-time experiences like live auctions, gaming, esports, and telehealth. However, challenges arise in scalability and flexibility beyond the browser-based, peer-to-peer scenarios. For optimal performance, WebRTC is recommended for audiences of 50 or less, and scaling requires the assistance of a streaming server to ensure video quality. A common workflow is to employ a custom CDN with WebRTC capabilities to transcode to adaptive formats like HLS or DASH for scalable distribution at the cost of latency.
Secure Reliable Transport (SRT)
SRT is an open-source protocol that emerged as an alternative to RTMP, leveraging the speed of UDP while incorporating TCP’s error-correction capabilities. This fusion results in low-latency, high-quality video delivery, making SRT prominent in live broadcasts. Supporting codec-agnostic audio and video, SRT offers tunable latency, typically sub 3 seconds, with the benefits of reliable transmission over suboptimal networks. However, its playback support is limited. SRT becomes invaluable when streaming over unreliable networks, addressing issues such as packet loss, jitter, and changes in bandwidth. SRT stands out for its unique blend of low latency and error correction and is slowly replacing RTSP with increasing native support in IP cameras.
HTTP-based protocols (HLS and DASH)
HTTP-based protocols, such as HLS (HTTP Live Streaming) and DASH (Dynamic Adaptive Streaming over HTTP), have become dominant players in last-mile delivery, particularly for Video on Demand (VOD) and Over-the-Top (OTT) services. These protocols leverage the ubiquitous HTTP infrastructure, allowing seamless delivery through regular web servers. While excelling in scalability and adaptability for various devices, HTTP-based protocols introduce higher latencies in live streaming scenarios, limiting their use in time-critical applications.
Design Considerations
Constructing a real-time video analytics solution demands meticulous attention to system requirements and a thorough assessment of the current streaming architecture. When working within the confines of an existing streaming setup, integrating an intelligence layer requires navigating within those bounds, potentially facing suboptimal performance. If building from the ground up, this is an excellent time to make informed decisions on using specialized hardware, ensuring optimal performance tailored to the specific task. Here we dive into a few design considerations that will help guide the decision-making process and set the foundation for a successful implementation.
Latency
Any system that moves video data from point A to point B and processes it with machine learning and computer vision algorithms will experience some level of latency. At this point the two major questions to consider are:
- Is real-time processing actually necessary?
- How much latency is acceptable for my application?
Frequently, stakeholders may find that insights delivered every few minutes can be equally valuable to those delivered within seconds. For example, a system that detects traffic patterns might only need to report anomalies if they persist for more than 10 minutes, allowing for some flexibility in latency.
First-mile Hardware
First mile hardware refers to both the camera sensors and the encoding hardware required to convert the raw video data into the proper protocol for transmission. The choice of camera hardware is heavily reliant on the application’s specific needs and objectives. Some questions to ask are:
- Are we restricted to existing hardware like IP cameras or specific broadcast cameras?
- Is this a single camera or multi-camera solution?
- When selecting cameras, what features are important? Resolution? Frame rate? Low-light performance?
- For outdoor deployments, what durability and environmental factors should we take into account?
Along with the choice of cameras is the choice of encoding hardware. IP cameras tend to support RTSP encoding out-of-the-box, with some now supporting SRT. Other types of cameras, like broadcast cameras, typically require encoding hardware. The main goal at this point is to understand how the video data is being captured and encoded before it’s transmitted for further processing and analysis.
Scalability
The goal here is to establish the current and planned scalability requirements. Some questions to consider might include:
- How many cameras are needed for a single system implementation?
- How dynamic is the system and workload?
- How many end users will ultimately interact with the live stream and its analysis?
It’s important to keep scalability at the forefront when designing a video analytics system. Building a solution that analyzes video data from a single IP camera is one thing. Ensuring that the same solution works with dozens, hundreds, or even thousands of cameras, each dynamically coming online, requires an entirely different approach.
Depth of Analysis
Establishing the depth of analysis often requires working backwards from the question:
- What objective am I trying to achieve through video analytics?
Some objectives are easier to achieve through video analysis than others. For example, consider two different objectives for a parking management system:
Objective 1: Count the number of open parking spaces
Objective 2: Detect, track, and catalog vehicles to ensure that those with proper access park in their dynamically assigned parking spots
The first objective is simple enough that it might be solved through tried and true image processing algorithms that can run on low-powered edge devices. The second objective will require real-time multiple object tracking algorithms working in conjunction with two or more deep learning models all running on a GPU. While both are solvable through video analytics, the depth of analysis has real implications on latency, camera hardware, and choice of computing hardware.
Edge or Cloud Computing
Choosing between edge computing and cloud computing is also highly dependent on the application objectives. Edge processing is ideal in scenarios with stringent low-latency demands, especially in environments facing bandwidth constraints or unreliable networks. This approach ensures that real-time processing occurs closer to the data source, minimizing delays.
On the other hand, cloud computing emerges as a powerful option when video analytics tasks necessitate substantial computational resources. The cloud is well suited for applications with dynamic workloads, offering on-demand scaling capabilities to efficiently handle varying processing needs. In practice, however, hybrid approaches often prove effective, leveraging edge computing for immediate, real-time processing and selectively forwarding pertinent data to the cloud for further analysis.
Adding Vision Intelligence to Streaming
Machine learning and computer vision algorithms are at the core of intelligent video analytics. Adding this layer of intelligence opens up a realm of possibilities for extracting valuable insights from live video data. While this technology is already deployed in various industries like security, retail, and manufacturing, there is a growing demand for video intelligence in live sports and gaming.
Intelligent video analysis plays a pivotal role in enhancing live streams by contributing to object detection, tracking, and video understanding. Two notable technologies in this domain are the NVIDIA DeepStream SDK and AWS Kinesis Video Streams. In this section, we’ll explore how and when each of these are used.
NVIDIA DeepStream
The NVIDIA DeepStream SDK serves as a comprehensive framework for constructing high-performance, managed video analytics applications both on edge and cloud infrastructure. It facilitates the creation of manageable video analytics pipelines that support image processing and deep learning inference with GPU acceleration.
For large scale deployments, cloud-native DeepStream applications can be containerized and orchestrated using Docker and Kubernetes. Edge deployments leverage NVIDIA Jetson devices, communicating with the cloud or on-premises hardware through message brokers like Kafka. Advanced analytics and visualization are typically handled downstream in the cloud.
Behind the scenes, DeepStream operates as a collection of plugins for the widely used GStreamer framework, specialized for deep learning video analytics and tailored for optimal performance on GPU hardware. Key plugins include Gst-nvinfer for TensorRT engine execution, Gst-nvtracker for multi-object tracking, and Gst-nvstreammux efficient multi-stream batching among others.
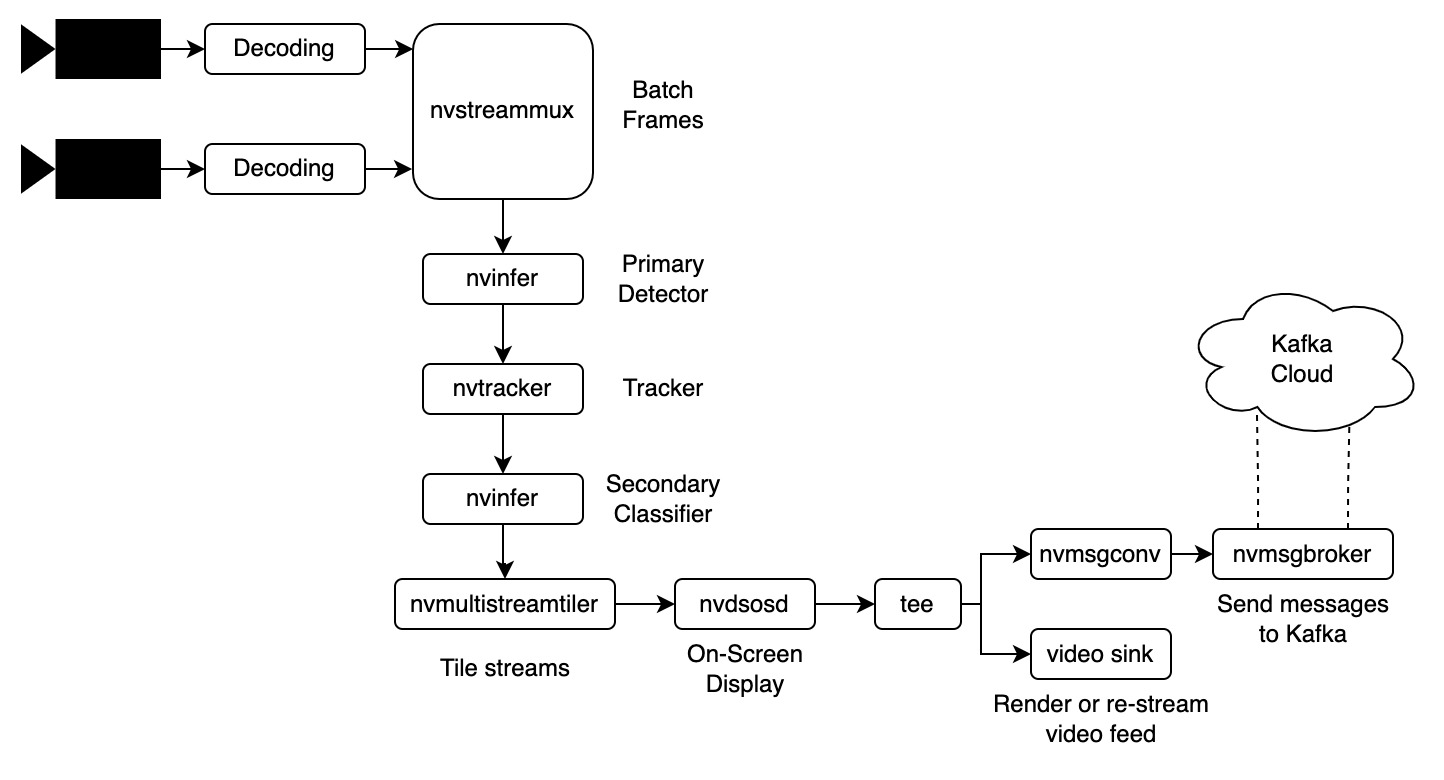
A typical DeepStream pipeline operates right after the first-mile contribution phase in a streaming application, receiving the encoded video data directly from the camera or encoding hardware. This configuration holds significant advantages for real-time processing, primarily due to its proximity to the data source. The close proximity ensures enhanced responsiveness. This is particularly beneficial for edge applications where swift response times are imperative, especially in systems interacting with additional hardware, such as those employed in industrial automation.
AWS Kinesis Video Streams
AWS Kinesis Video Streams (KVS) simplifies the secure streaming of video from connected devices to AWS for playback, analytics, machine learning, and other processing needs. Offering automatic provisioning and elastic scaling of infrastructure, KVS efficiently handles the ingestion of streaming video data from countless devices. It provides durable storage, encryption, and indexing of video data accessible through user-friendly APIs. KVS supports live and on-demand video viewing, empowering the rapid development of applications leveraging computer vision and video analytics. In the context of the live video stream delivery pipeline, KVS stands out as a solution for the processing and distribution phase.
With recent updates, KVS also enhances the building of scalable machine learning pipelines for analyzing video data through integration with AWS Rekognition, AWS SageMaker, or other custom media processing applications.
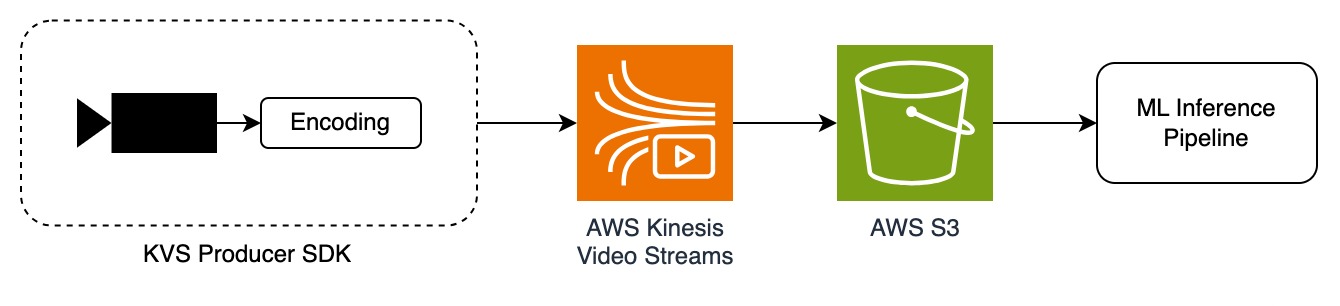
In a typical video analytics solution, a KVS Producer SDK, operating at the first-mile contribution phase, segments video data into fragments and sends the fragments to the KVS service where they are indexed and stored in AWS S3. For machine learning inference workflows, the KVS service is configured to generate images from the source video data fragments at a specified sampling interval and image quality. These images are also placed in an S3 bucket where they can be used for downstream analysis.
In contrast to DeepStream, where inference operates on the video data in real-time, KVS offers a set of tools to index and store video data for downstream analysis on a per-image basis. While this may introduce latency, this approach allows for deeper analysis at scale. In the end, where the intelligence layer is added in a live streaming setup depends on the overall application and objective.
Case Study
In a recent engagement, Strong worked with a sports and gaming company that was looking to automate several officiating processes through intelligent video analytics. Similar to video assistant referee (VAR) systems in soccer, the system would enhance existing officiating practices by automatically detecting and tracking athletes and ensuring athletes adhere to regulations through automatic action recognition.
The Problem Setup
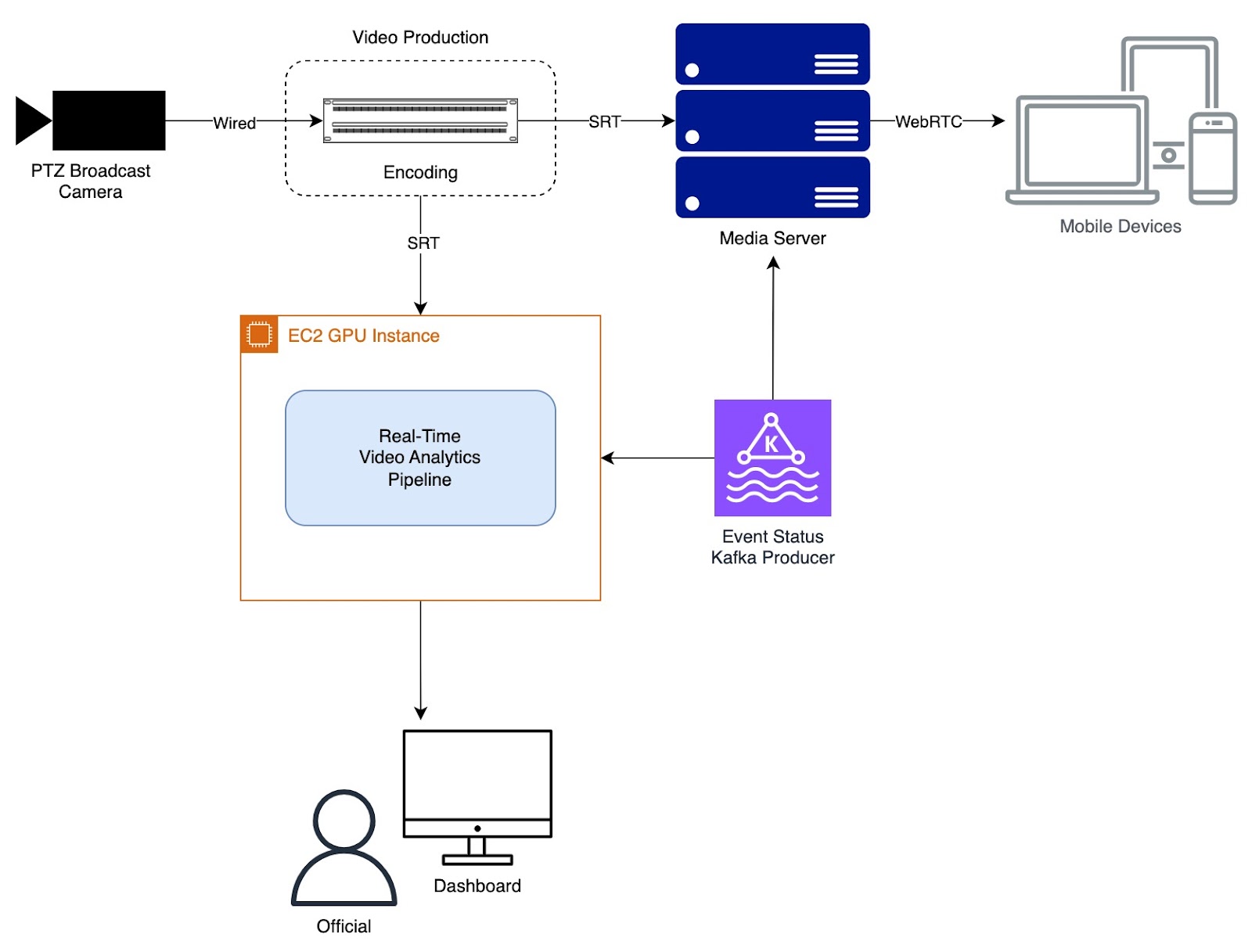
The solution needed to be easily scaled to multiple venues, thus eliminating the use of a custom camera setup, opting instead for ingesting the live feed directly from a single PTZ broadcast camera. For the same reason, edge computing is ruled out in favor of easily scalable cloud computing. Additionally, it was imperative that results be delivered within seconds in order for them to be useful for time-critical officiating purposes.
The Solution
Strong built a real-time video analytics pipeline that integrates with existing streaming infrastructure, receiving an SRT stream directly from the first-mile contribution phase of the delivery pipeline. The intelligent video analytics layer consists of a set of orchestrated services running on a GPU-equipped AWS EC2 instance for accelerated model inference. Within the pipeline, the SRT stream is decoded and fed to multiple TensorRT inference engines, all running in parallel, that detect and track athletes as well as perform action recognition. A Kafka consumer service controls inference execution for seamless transitions between events. Results are then published, via an API, to a dashboard for review by officials.
The solution produces actionable results in real-time and automates previously tedious officiating processes, saving end-users time while enhancing accuracy. By design, the video analytics pipeline executes entirely in the cloud, allowing for quick onboarding of new venues as well as efficient scaling with multiple venues hosting events concurrently.
Conclusion and Resources
Intelligent video analytics applications are a powerful way to extract insight from visual data. With wide-ranging applications in industries from security and manufacturing to sports and retail, it’s likely there’s existing problems waiting to be solved through video analytics.
At Strong, we build custom, robust, and scalable video analytics solutions that allow companies to make smarter and faster decisions through their video data. Reach us at contact@strong.io to learn more about how to transform your video data into actionable insights.