

Introduction
In recent years, advancements in machine learning have had a significant impact on various industries and aspects of our daily lives. One area that has seen significant growth is Computer Vision (CV), which involves the use of machine learning to process images and extract meaningful information from them. CV systems have a wide range of applications, including manufacturing, automotives, sports analytics, farming, and retail.
One example of CV in action is the use of Advanced Driver Assistance Systems (ADAS) in cars. These systems have features such as forward collision prevention, lane keeping, blind spot detection, and pedestrian impact avoidance, and are estimated to have the potential to prevent 40% of all crashes involving passenger vehicles, 37% of all injuries, and 29% of all fatalities in the US.
While CV systems may seem to rely solely on deep learning, many systems still utilize traditional techniques in conjunction with deep learning. The question of when to use each approach and how to combine them remains nuanced. In this article, we will discuss traditional CV techniques and deep learning-based approaches, and provide insight into when and how to use each method.
Traditional CV

Traditional CV involves the process of feature engineering, which involves developing algorithms specific to a certain task. The defining characteristics of objects of interest within an image must be defined, and the engineer utilizes their domain knowledge and expertise to develop the system using traditional image processing tools.
For example, in the case of pedestrian detection, a common descriptor used is the Histogram of Oriented Gradients (HOG). The image is typically divided into fixed-size tiles, and the descriptor is derived for each tile. A classifier, such as Random Forests or SVMs, is then used to predict whether or not a specific tile contains the object of interest.
One drawback of this approach is that it is not able to detect objects of different sizes within an image. To overcome this, image pyramids are often used, which involve applying the detection algorithm on several resized versions of the image.
One advantage of traditional CV solutions is interpretability. Because the engineer has defined exactly what defines the object of interest and where and how the algorithm should look for it in an image, it is possible to analyze and understand cases where the system works well and where it falls short.
One of the major drawbacks of traditional computer vision is the process of feature engineering itself. As previously discussed, this approach involves developing algorithms specific to a certain task, such as pedestrian detection, by defining the characteristics of the object of interest within an image. However, this approach is often not scalable and requires the development of new algorithms for each object of interest that is to be detected.
Additionally, traditional computer vision systems often lack accuracy and reliability when compared to human perception. This limitation has hindered the application of these systems in real-world scenarios.
Deep Learning
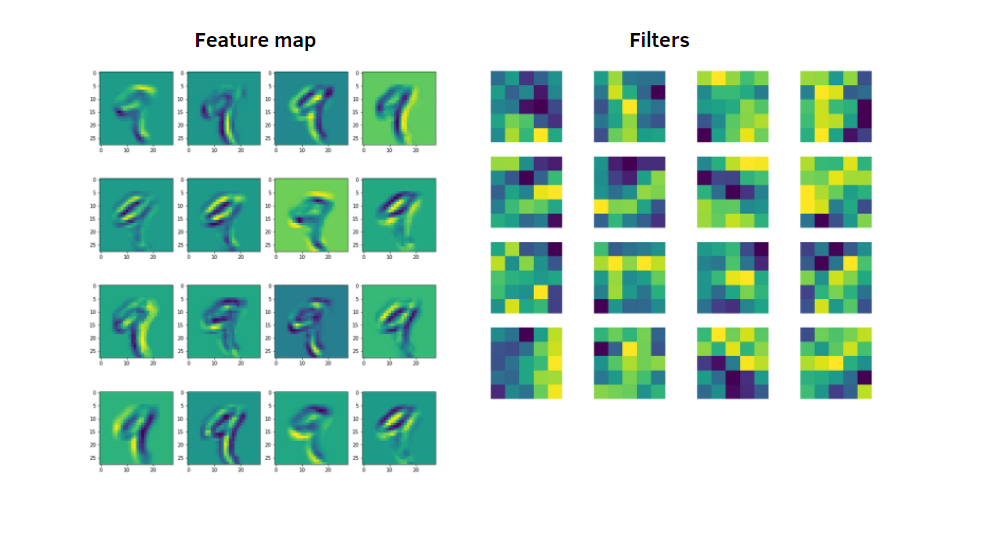
Deep learning is a branch of machine learning that involves the use of neural networks with multiple layers. In 2012, deep learning made a significant breakthrough in CV, largely due to advancements in GPU technology that allowed for the training of sophisticated neural network architectures. One such architecture is the Convolutional Neural Network (CNN), which is optimized for processing images.
The major difference between CNN and traditional CV is that CNN does not require feature engineering. Instead, CNNs are trained using a dataset of labeled images. The type of label required depends on the type of vision application, such as image classification or object detection. During training, the CNN model adjusts its internal weights and connections to optimize its performance on the given training images.
The main advantage of CNN is that they do not require feature engineering, and are capable of achieving high accuracy and reliability on common vision tasks. However, CNNs require a labeled dataset for training, which can be time-consuming and expensive to acquire. Additionally, CNNs are computationally expensive and require powerful computing resources for training and deployment. However, as deep learning continues to evolve, CNNs are becoming more lightweight and accurate.
Considerations in Production
When deciding between traditional CV and CNN for a production system, it is important to consider factors such as computational resources, availability of labeled data, and explainability.
CNNs tend to deliver more accurate and reliable results, but they require more computational resources and a comprehensive labeled dataset. On the other hand, traditional CV can be difficult to develop and maintain, as it requires feature engineering for each object of interest.
One important consideration is the availability of pre-trained models for common vision tasks. Many pre-trained CNN models are readily available for use in a production system, without the need for collecting and annotating a dataset.
Explainability is another important factor to consider, particularly in critical applications such as medical imaging. While CNNs can achieve high accuracy, it can be difficult to predict their behavior due to the millions of internal parameters that are optimized during training. Traditional CV, on the other hand, can be more interpretable as it involves domain-specific feature engineering.
In many cases, it is common to see production systems that integrate both traditional CV and CNN to solve a certain problem. For example, traditional CV can be used to pre-process camera streams before running the data through a CNN. The information generated by CNN can also be fused with that generated from traditional CV to achieve a more robust result.
Contact Us
Contact Strong to find out how we help build state of the art vision systems across many industries.

