


If the cloud is the realm of abundance, the edge is one of scarcity. Unlike the cloud, with its elasticity and on-demand resources, the edge is a rigid, often punishing environment in which to deploy machine learning models. Forcing complex computer vision models to run on a device with limited memory, minimal power, and overall scant resources compared to even a desktop computer can often feel like forcing an elephant through a pinhole.
But if you’re struggling to fit your application onto something with all the heft of a Raspberry Pi, know that it can be done. Working with the edge requires abandoning the profligacy of the cloud and becoming a computational miser, accounting for nearly every last one of your model’s bits. In our experience of deploying ML models on the edge, we’ve picked up a few broad tips to help you shrink your perspective down to the edge’s level.
What is edge machine learning?
Most people’s day-to-day experiences with machine learning typically occur with models deployed to the cloud. Google Translate, Facebook’s news feed algorithms, Amazon Alexa, and the majority of machine learning technologies people are familiar with aren’t executed on the client side of the application. Instead, these massive models perform all their computation in large cloud-based environments, and the app receives instructions remotely from the cloud.
Edge machine learning localizes this processing to an embedded device itself. Rather than transmitting data for a cloud-based model to process, the device --- whether it’s a phone, a vehicle, a robot, or a Raspberry Pi, or anything else --- stores the model onboard and performs all the computation on its own. By running the model locally, edge ML can be run whether or not there’s a reliable internet connection, reduces latency, avoids storing data in a server, and can be deployed without concern for scaling cloud architecture.
When should you use edge machine learning?

You should conduct careful evaluation to determine if deploying to an edge device is the right requirement for your application. In doing so, it’s important to consider that building ML apps for deployment on embedded devices involves far greater complexity and comes with limitations that cloud systems can often simply scale their way out of.
Here are some considerations for when you might want to build your ML app for the edge instead of the cloud:
Can your model fit on the embedded device?
Optimizing your model so that it can fit on a small device and run quickly is a core part of developing machine learning models for the edge, and as we’ll see, there are a number of tricks you can employ to crunch your model down substantially. But optimizations have their limits, and models can only be shrunk down so much. If you’re using truly massive machine learning models --- like state of the art Transformer architectures for natural language processing or vision --- getting your application to work on the edge may simply be infeasible (for now!).
Are the operations in your model supported?
Many edge ML frameworks support only the most common operations. While you may be able to use a model that contains non-supported operations by running on CPU, you will sacrifice substantial efficiency and performance. For example, the deformable convolutions that lead to increased performance in several state-of-the-art anchor-free detectors may not be compatible with your hardware platform. To resolve these issues you can either switch to a different architecture entirely, or replace the unsupported operations with supported ones (although you may expect a drop in accuracy in doing so). Frameworks are often in rapid development, and you may want to experiment with nightly-builds to resolve verbose and non-specific bugs.
Are safety and 100% reliability a concern?
Because they don’t require constant connectivity to servers, edge ML apps are by their nature less vulnerable to network hiccups. For some applications, sub-100% uptime doesn’t present substantial problems, even if it poses issues for the user experience. If your smart speaker doesn’t hear you ask to play Miley Cyrus, the party may stop, but everyone will be ok.
For other applications, however, transmission latency or downtime is simply not acceptable. Self-driving cars need to process data onboard so that the car can continue operating whether it’s in a city or the desert. Security applications require the same reliability to keep network problems from becoming safety hazards, or from preventing verification systems from malfunctioning and locking people out of buildings. In short, if losing connectivity could result in an extreme disruption or actual physical harm, you’re probably best off finding a way to make your app work on the edge.
Should your data remain on device?
Given the nature of the kinds of data that edge ML apps might process, it’s sometimes best to minimize the transfer of sensitive information over potentially vulnerable networks. The most familiar example of this is Apple’s Touch ID and Face ID, both of which store and process biometric data on the device. While this is also critical to ensuring that people can access their devices even when they’re offline, it also keeps highly sensitive information --- users’ fingerprints and facial features, tied to their personal identities --- out of centralized repositories, where they can potentially be accessed by malicious actors.
Alternative techniques, like federated learning or processing hashed data remotely, can remove the need to process data entirely on-device. These techniques, however, often require complex infrastructure to work effectively.
What are the major edge ML frameworks?
Organizations have released and sponsored a number of open-source edge ML frameworks, each with their own advantages and limitations. Here are the main players:
TensorFlow Lite
TensorFlow Lite is a lightweight version of TensorFlow focused primarily on optimizing for small binary size and efficient execution of ML models on ARM devices. TensorFlow Lite is the required framework for deploying on Google’s Edge TPU and integrates the best with TensorFlow frozen graphs.
PyTorch Mobile
PyTorch Mobile is the version of PyTorch designed to be run on mobile devices and has native interpreter support for both Android and iOS. It has less specialized hardware acceleration support (i.e. GPU, DSP, NPU) compared to TensorFlow Lite and integrates best with models developed with PyTorch.
TensorRT
TensorRT is NVIDIA’s inference acceleration library, which performs model quantization, layer fusion, kernel tuning, and more. TensorRT is designed specifically for NVIDIA GPUs and can be used in either a cloud GPU server or NVIDIA’s Jetson embedded device environment. It natively integrates with TensorFlow and MXNet, and can accept models saved in ONNX format.
OpenVINO
OpenVINO is highly optimized for Intel CPUs, integrated graphics processors, Neural Compute Stick, and Vision Processing Unit. Its model optimizer is cross-platform and supports models built with TensorFlow, PyTorch (through ONNX), Caffe, MXNet, and more. OpenVINO provides an inference engine which compiles the converted OpenVINO model to allow for optimized execution on Intel devices, including CPUs.
Core ML 3
Core ML 3 is Apple’s in-house machine learning framework, optimized for Apple hardware with minimal memory footprint and power consumption. It has special support for fine tuning models on-device with the user’s local data, and as such provides great privacy support by avoiding the need for a centralized server. The framework supports building, training and inference, and supports model conversions from popular third-party frameworks such as TensorFlow, PyTorch, and scikit-learn.
Embedded Learning Library
The Embedded Learning Library is Microsoft’s open-source project for machine learning that uses a cross-platform compiler specialized for resource-constrained hardware.
What hardware solutions exist?
Edge hardware spans a wide range, from devices that consumers carry with them every day to specialized systems. When choosing the correct hardware platform for deployment of your edge ML product, it’s important to consider the power constraints of your total system, speed requirements, planned ordering volume, and hardware connectivity and integration. Here's an overview of the hardware that edge ML applications can be built for.

Consumer devices
Smartphones and tablets are increasingly designed with ML applications in mind. Processors on newer iPhone models contain neural processing units — cores dedicated to machine learning applications. These cores integrate well with Apple’s proprietary machine learning framework, Core ML, to enable hardware acceleration, and even allow developers to have models train on device, achieving model outputs that are highly customized to individual customers while maintaining a high level of privacy.
Meanwhile, Google's Pixel smartphone lineup recently announced the inclusion of a proprietary Tensor chip. Among other things, the Tensor chip will boost the Pixel’s abilities in computational photography, which includes processes like stitching together multiple nighttime photos to create a single, optimal image, AI based portrait modes, and more. Though Google hasn’t yet announced how its dedicated machine learning chip will be used, it is expected that video quality from Pixel phones could greatly benefit, thanks to subfields of computer vision like super-resolution.
Microcontrollers and microcomputers
Microcontrollers and microcomputers like the Raspberry Pi and other ARM based devices, while not specialized for deep learning, are affordable, extensible, and modular, facilitating external hardware integrations like adding camera or light modules. Running complex models, however, will push the limits of the processing speed and memory of these devices. Increased compute power can be added via PCIe and USB accelerator boards as described below.
GPUs
GPUs provide general processing for all kinds of graphic intensive tasks. The actual rendering that GPUs were traditionally engineered for, which involves pixel translation and object rotation, ultimately boils down to performing matrix multiplications. Since these are the same mathematical operations that are carried out inside deep learning neural networks, GPUs are well suited to accelerating operations needed in neural networks.
NVIDIA Jetson offers a family of modules equipped with NVIDIA GPUs in a small form-factor. Unlike Google’s Coral family, Jetson has a wider range of products with varying degrees of computational power. Similar to Google’s Coral product line, NVIDIA offers developer boards, SoM single-board computers, as well as PCIe and M.2 accelerators suitable for production environments.
Edge TPUs
GPUs, however, are designed to handle more tasks than simply image transformation, and they’re also optimized for video encoding, video compression, and shading, and so on. Tensor Processing Units (TPUs), Google’s custom chips specifically designed for deep learning tasks, remove all these additional features from GPUs, therefore making them even more specialized for specifically deep learning tasks. Edge TPUs are further optimized TPUs with low-power consumption designed for edge devices. They have an extremely small physical footprint and integrate well with TensorFlow Lite.
Development products that use Edge TPUs include the Google Coral development board, single-board computer with an Edge TPU embedded, and USB accelerators, a USB stick that’s best suited for bringing Edge TPU acceleration to existing systems. For deployment, PCIe accelerators are production-ready devices that integrate Edge TPUs with production systems.
Custom SoCs
Additionally, a number of hardware manufacturers including Ambarella, NXP, Texas Instruments, Xilinix, and others produce custom embedded devices tailored to various real-world applications. From FPGAs to other custom ML SoCs, the landscape of embedded hardware aimed at AI inference is rapidly growing.
What are the critical steps to deploy models on an embedded device?
Improve your model without increasing its size
Since scarcity is fundamental to the edge, successfully deploying a ML model on an embedded device typically means making your model as small as possible while still maximizing its accuracy. Whereas refining a model for the cloud or even desktop systems can often be accomplished by adding capacity, the edge’s hyper-economical demands mean that your model’s performance has to increase while also not growing substantially, if at all, in size. This can be handled, for example, by more complex training regimes (e.g., model distillation), more efficient operations like depthwise convolution, or alternative architectures.
Become familiar with optimizations for the edge
In addition to improving your model without increasing its size, there are ways to directly decrease its size. Consider regularly incorporating these techniques when optimizing for the edge:
- Quantization: Turning 32-bit floats into 8-bit (or smaller!) integers. By quantizing your model’s weights, one can greatly decrease the space the model needs and increase inference speed while typically incurring only minimal costs to accuracy. This can be accomplished after training (post-training quantization) or during (quantization-aware training). Quantization-aware training minimizes accuracy loss during inference at the expense of a slightly more complex training regime.
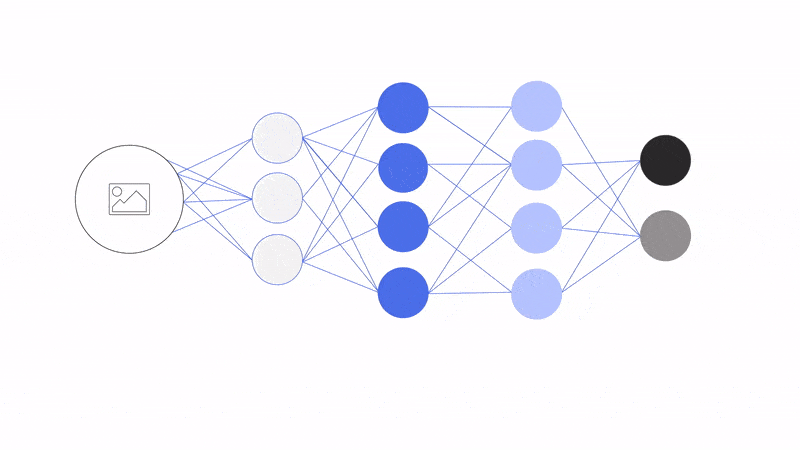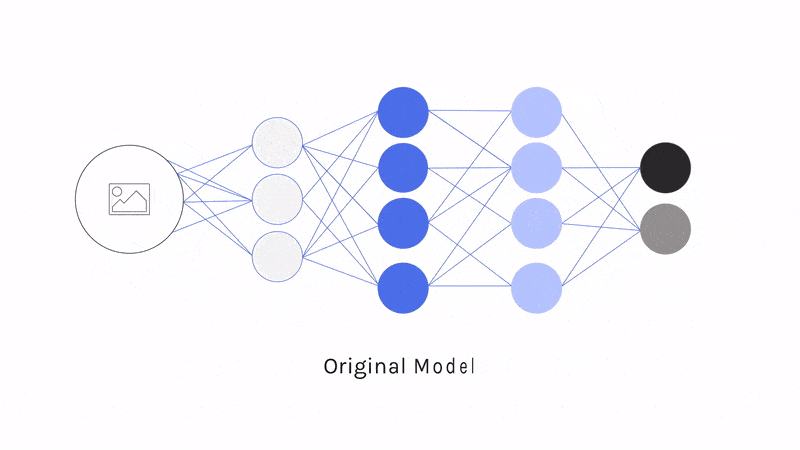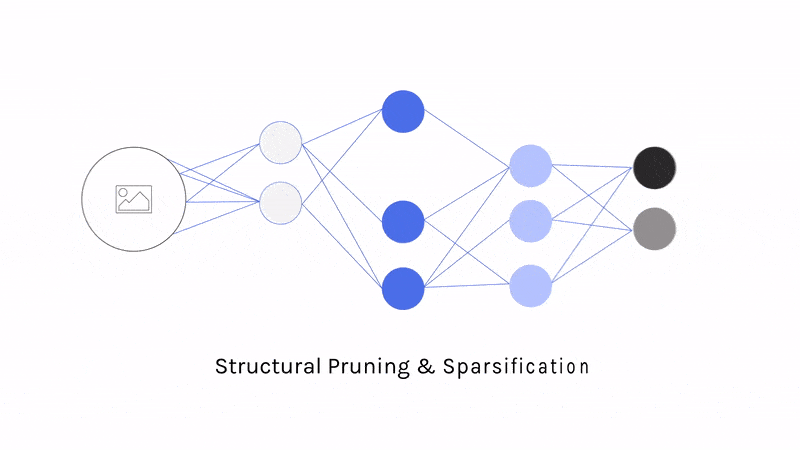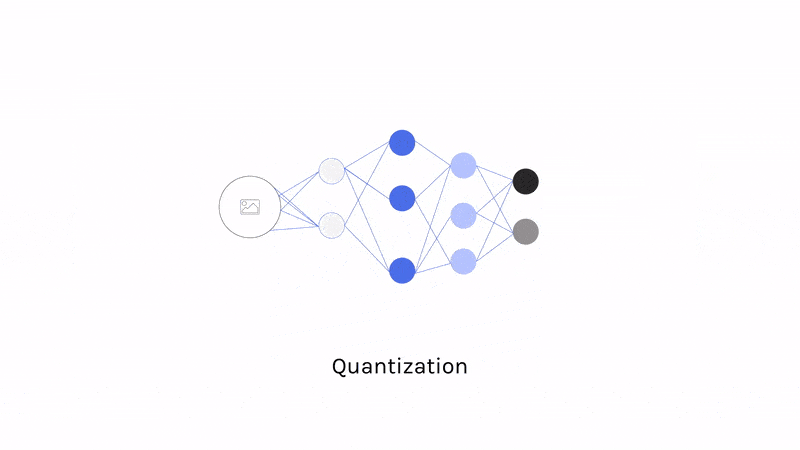
- Structural pruning: Structural pruning algorithms determine, for example, entire channels of filters that have the least impact on the final classification of a network and remove them entirely. This reduces both the binary size of a model and its memory footprint, since the dimensions of weight tensors are reduced, translating to a smaller memory footprint. It increases inference speed as well, as there are less calculations to make during a forward pass.
- Weight pruning (sparsification): Unlike structural pruning, weight pruning “turns off” connections by setting specific weights to 0. Through compression algorithms that specialize in efficiently storing sparse arrays, the binary size of a model can be reduced. Since the weight tensors remain the same dimensions, the memory footprint of a model after sparsification remains the same. However, some inference engines can smartly translate these 0 weights into "Non-OPs" so that no calculations are actually performed. By skipping a significant portion of multiply-add operations, a sparsified model can benefit from a significant inference speed boost. TensorFlow Lite has very recently introduced native support for inferencing with sparse networks.
Expect trial and error
Many of the problems encountered in getting models to run on the edge occur at extremely low-levels of the machine: You’re not just dealing with syntax errors, but incompatibilities with your model and the device’s underlying system architecture. Debugging things at this level is, predictably, more complicated and less clear-cut than searching Stack Overflow for the solution to a Python exception.
Other optimizations also won’t clearly succeed or fail until you try to execute them – for example an operation may be transferred from TPU to CPU based on the size of a tensor with no warnings, only to be discovered by testing latency at inference time.
In other words, machine learning at the edge requires not only patience and perseverance, but also clever workarounds for when things don’t go quite as planned. Ultimately, however, the benefit of having a product that can run real-time inference regardless of connectivity can substantially outweigh the challenges of deployment.
Contact Us
Contact Strong to learn more about deploying to embedded devices and how we help companies of all sizes move from ML PoC to real-world products.
