

With the Tokyo 2021 Summer Olympics in full swing, viewers can expect to see not just the world’s premier athletes, but also an array of advancements in how broadcasters enhance sporting events. Computer vision applications can provide deeper information about what’s happening on screen, from the speed at which a javelin was thrown to the exact altitude a high jumper reached. And these same applications can be used for athletes and coaches themselves, giving them precise insights into their performance relative to their opponents from both historical and live video.
Our team at Strong is composed of several competitive runners and, to mark the summer games, Strong built an application to track runners in live video and find out how close we are to standing on the Podium (it's closer than you might expect!).
Computer vision can provide unique information to enhance live broadcasts and engage viewers, as well as to provide detailed insights for athletes and coaches themselves
While you’ll often hear about the latest model providing state-of-the art performance, focusing on a single deep learning approach often misses the mark. Building real-world computer vision systems typically requires a dynamic interplay between multiple complex algorithms and careful orchestration of these components. In this example, we highlight our process to localize and derive metrics from Olympic track & field.
System Overview
Here’s an overview of how it works:
- We estimate the 2D poses of athletes from each frame
- We track athletes by associating frame-over-frame to maintain their unique identities
- We use information from the scene, such as unique visual features and camera motion to perform ‘calibration’ of the camera and derive important properties of the camera like pan, tilt, zoom, distortion, and camera focal lengths.
- We project the positions of athletes into the real world, from 2D to 3D GPS coordinates
- We use the sequence of 3D positions over time to determine metrics like stride length, speed, and finish order
Below, we explain each step in detail.
Detection & Tracking
Traditional approaches for object tracking follow the “track-by-detection” approach: A model is used to detect an object of interest in a frame and a separate data association process is used to determine the identity of that object. Using this approach often involves complex association strategies that are error prone, difficult to tune, and incorporate substantial manual logic.
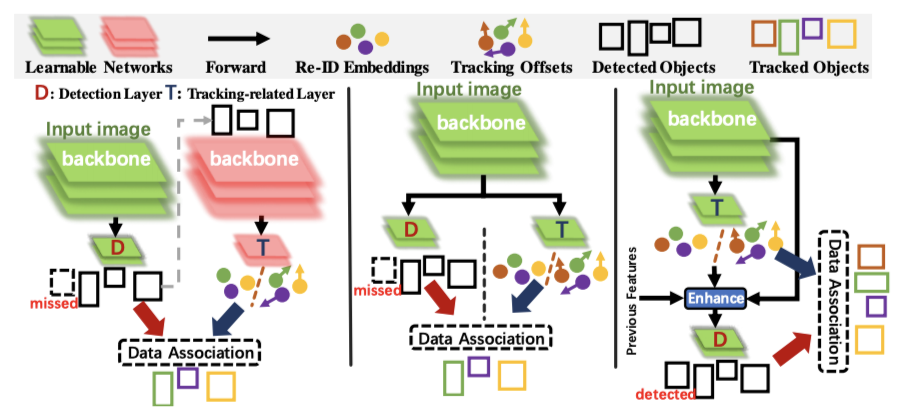
We instead leverage more modern approaches that incorporate simultaneous detection and tracking to reduce complexity and increase accuracy. We use anchor free methods as the detection backbone to enable faster detection and better performance by reducing the need for complex anchor box related hyperparameters and calculations. Tracking is performed by inferring tracking offsets between targets of interest between sequential frames. Additionally, by incorporating tracking information back into detection, our detection model becomes more robust to complex scenarios like fast motion and occlusion – an essential component for any sports tracking system.
Beyond the base tracker, we can leverage fundamental constraints of the scene — specifically that there are a known number of athletes in a video — to simplify the problem. This enables the use of more accurate tracking verification by incorporating a long-term memory that remains robust to visual changes by illumination, occlusion, and other visual scene changes.
Camera Calibration

Knowing the position of athletes in 2D from detection and tracking, however, only gets us part of the way there. In order to actually derive metrics like speed and stride length, we need to know where runners are in physical, 3D space.
To know the position of runners, we need to derive camera information like pan, tilt, zoom, distortion, and focal length to project a given coordinate within the frame to a ‘real-world coordinate’. This allows us to determine where a runner is relative to the physical camera that captured the video.
The challenge is that these parameters change very quickly — runners move fast, and the camera pans, tilts, and adjusts its focal length quickly to keep up with the athletes. So one option is to use brute-force by annotating whose sizes we know in every single frame. The more objects whose features we know, the easier it is to use that information to find the features of objects we can’t annotate. But that solution is, predictably, completely infeasible for our project, since that level of annotation would be interminable.
Instead, we use an alternative approach: self-calibration, which uses known correspondences between points on the screen and points in the real world to derive information about the camera’s position, intrinsics, and extrinsics through optimization, and updates based on scene motion and an underlying field model.
Offline Calibration
First, we start by selecting a set of landmarks both in the video frames and in the real world. These can be anything from markings in the field or the lanes and numbers on the track, but they need to be on the same ground plane. We leverage Strong’s open source spatial annotator app to establish these correspondences between the 2D points in the video frame and the 3D points in physical space. For each subsequent frame we extract visual features and track them from one frame to the next. This allows us to find an image-to-image transformation called a homography, which we then use to directly update the camera pose given the constraints of the system motion.
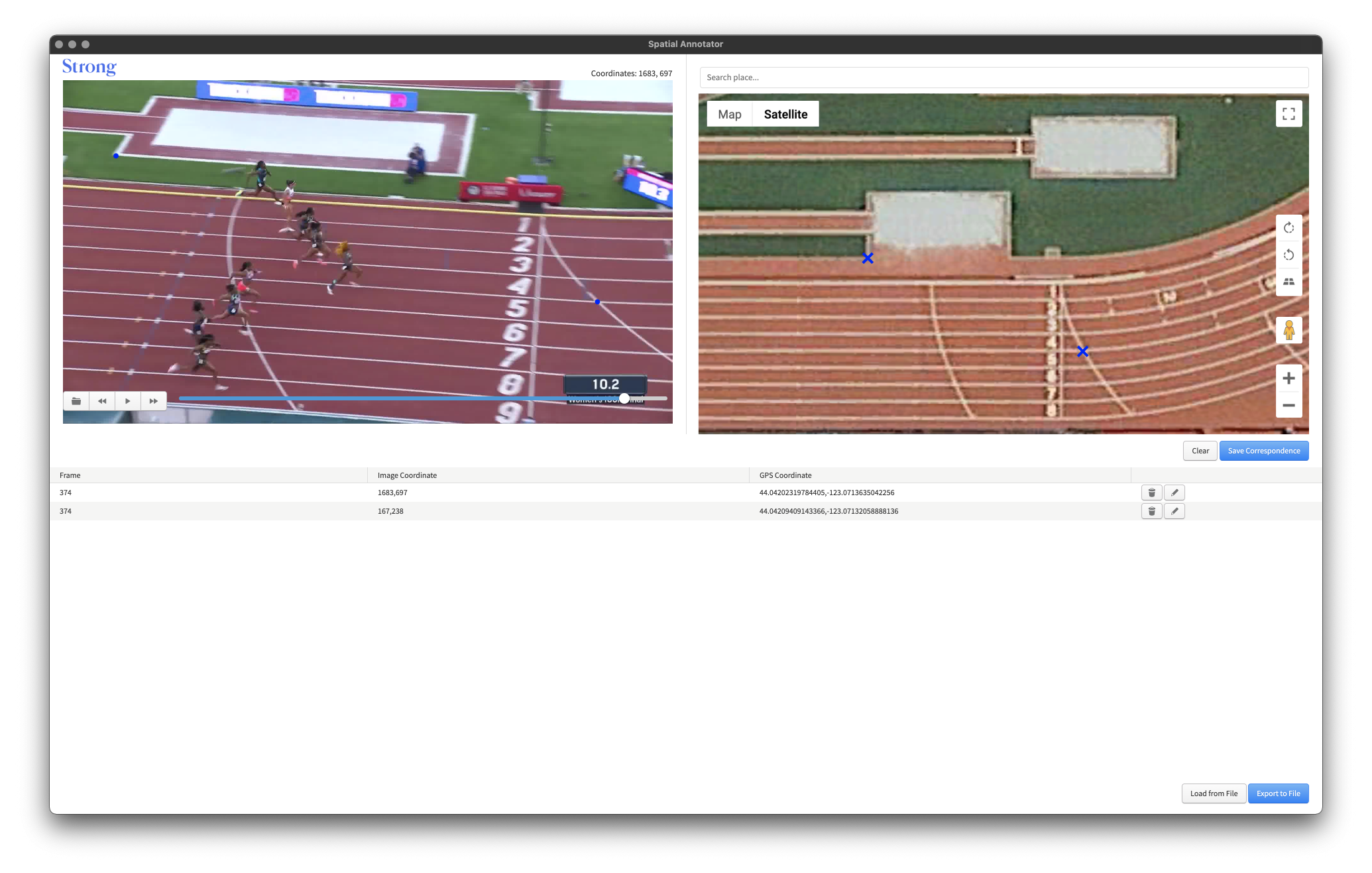
Since slight errors tend to accumulate in this approach, a global optimization (or bundle adjustment step) is performed to minimize the keypoint reprojection error and adjust the camera poses. An offline map is saved in the form of a set of keyframes with a known camera pose.
Online Calibration

Once a map is created, any new race (including live races!) can be calibrated in real time by determining the relative offsets from previously known camera pose and visual feature matches, along with motion tracking and projection. These approaches are commonly used in SLAM (simultaneous localization and mapping) systems to identify previously seen locations. This, for example, is how your Roomba knows where it’s been in your room before. We leverage state-of-the-art approaches to integrate global and local visual features with fast geometric verification to enable real-time relative camera calibration.
Metrics
Finally, after extracting the 3D real-world poses of athletes, we can calculate metrics like finish order, speed, acceleration, stride length, gait, and more. Ultimately, these metrics can be compiled for an individual athlete over time to monitor changes in their performance relative to their training routines, or to make predictions based on relative changes as they near the big race day. Or, they can be used to tell us that the best sprinter at Strong, Cody Dirks, is a mere 34% slower than Usain Bolt's 2014 record — Paris 2024 here we come!
Contact Us
Contact Strong to learn more about our expertise building computer vision systems for real-world challenges.

