

What if you could predict your customers' behaviors — such as purchasing your product, seeking support, or switching to another provider — before they happened? This information could open up new, proactive strategies for your organization; for example, converting someone from likely going to churn to upgrading to a more expensive product.
Recently, we worked with a small Software-as-a-Service (SaaS) startup to implement such a prediction engine and, in the process, opened their eyes to a critical new strategy for lean growth.
They came to us with a simple problem: after years of solid growth, Monthly Recurring Revenue (MRR) increases were beginning to slow. They had spent most of their time to this point focused on their product (adding new features, re-designing its interface, and making the tech behind it more reliable), and now they wanted to focus on their customer acquisition. Over 2000 users were signing up for a 10-day free trial of their product each month, but only around 3% of them were converting to a paid subscription. What led trial users to subscribe? And how could they increase this conversion rate — a key metric of their company’s health?
An Experiment Yields New Insight and Opportunity
Early analyses of their typical support interactions with their customers made two things very clear. First, many of their users who submitted support tickets had trouble getting started with their product: they found the initial setup confusing and often had to leap a few technical hurdles in order to get it working. Second, a large number of users never submitted any support tickets, but never used the product either — they signed up and then disappeared forever.
To better understand the typical customer and, moreover, their issues in getting started with the product, we encouraged the company to perform a simple experiment: hire some extra support personnel and, for an entire month, call or email every single person who signed up for a trial. Ask them what they think of the tool, if they are having any problems, and help them fix them. This turned their onboarding process from almost completely ‘hands-off’ into very ‘hands-on.’
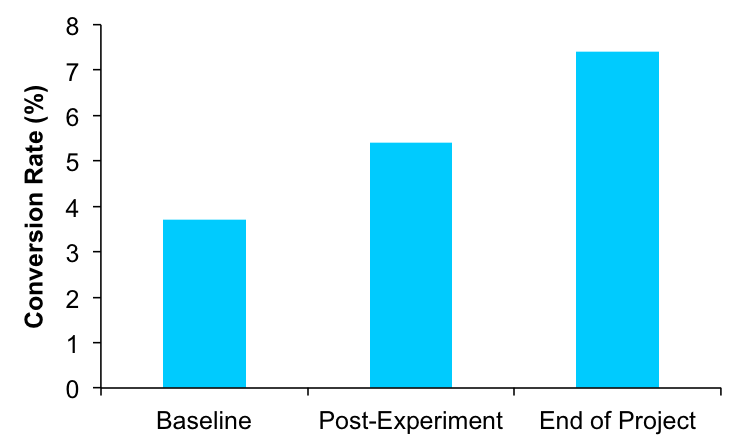
We learned several things from this experiment. First, users were indeed having lots of technical issues. But, more importantly, these calls really helped: most of their questions and issues could be readily addressed in a short conversation. Their conversion rate climbed from 3.7% to 5.4% by the end of the month. Finally, just like we saw in the support tickets, many users were simply not interested in purchasing — they were not in the target market (it was a B2B product) but signed up only to use a free tool that the company offered to all trial users.
Now, if this larger support team was practical for the long run, this would have been the end of our story. They would have continued to scale their support personnel and continued with the hands-on sales process.
But, as is the case with most startups, this company wanted to take a more lean strategy. They only wanted to keep as many people as it would take to work with those users who were actually in their target market — the ‘high-value’ trial users who were most likely to convert if they could install the product successfully.
This created an interesting opportunity: If we could find a way to identify the high-value trial users automatically, we could have customer support personnel focus their attention on these users and get the same conversion rate impact with less overhead expense.
Our Solution
We proposed to build and integrate a live prediction engine that could learn from historical data what kinds of users are likely to convert and, in real-time, generate conversion probabilities for current trial users. By feeding this information to the company’s Customer Relationship Manager (CRM), customer support personnel could then focus on high-probability/high-value users with their installation intervention technique.
Gathering and Enriching the Data
Robust predictions benefit from having high quality and easily accessible data. Thankfully, we had previously helped this company to set up their data strategy and pipeline, ensuring they were following the essential rules that we suggest should be part of any startup’s data strategy and were ready to integrate data tools and products into their business operations.
For each user on a trial, we had standard information like their name, email, the number and timing of their logins, the number of times they had used various parts of the product, and their success rate with using the product, as well as several other metrics unique to their experience with this particular product.
We enriched these data with other data points that we thought may be important given what we knew about the kinds of customers who had historically purchased the product, such as their gender (predicted using their first name and a name-gender database), the week day they signed up, the hour they signed up, and their email provider (tip: @yahoo.com accounts don’t buy many B2B products).
In total, we had 70 unique datapoints for each customer, many of which were dynamic — changing each day of the 10-day free trial.
Testing Machine Learning Algorithms
We next auditioned several different machine learning algorithms to see which one would do the best job predicting from these data whether or not a user would convert to a paid subscription. Our goal was to balance the simplicity of the model (making it faster, easier to implement, and less likely to blow up) with its accuracy.
We compared different models using their AUC (Area Under the Curve) scores. AUC scores are helpful because they simultaneously capture the sensitivity of the model (whether it tends to predict a conversion when a conversion occurs) as well as specificity (whether it tends not to predict a conversion when a conversion does not occur). We trained each model on data from one year, then tested it on new data it hadn't seen from the subsequent 6-month period.
We began with simple logistic models (with predictors selected using Lasso). Our best logistic model had a 78% AUC. Moving upward in complexity, we then tried a random forest model (80% AUC) before finding great success with a well-tuned gradient boosting model (93% AUC).
While gradient boosting yielded some promising results, it was doing so under a somewhat unrepresentative situation. Our gradient boosting model never accounted for the day-by-day nature of the day — instead, it just took all the data up to the current point as one big blob without any temporal structure. We were testing the models’ predictions on 6 months of new data where, for each user, it could see all 10 days of their trial period at once. In the real implementation, the model would only get to see the data from day 1, then day 2, day 3, etc. The model didn't perform as well when we tested it with more realistic data.
This led us to implement a modeling technique which explicitly includes the temporal structure of the data — a Recurrent Neural Network (RNN). It did incredibly well, with a 95% AUC in our representative tests! As you can see in the plot below, it had above-chance accuracy from the first day of a user’s trial, but became even more accurate through the full 10 days.
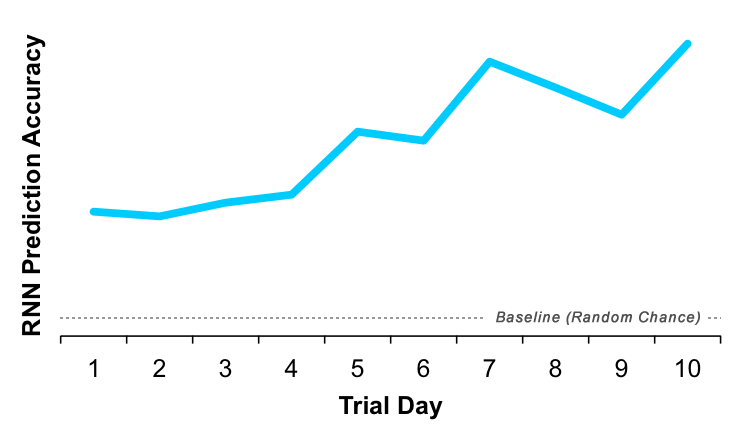
Despite the added complexity, we settled on this as our final model.
Integrating the Predicted Conversion Probabilities
After doing some more testing, and scaling up the model to work with all the live data, we integrated its predictions into the company’s CRM. Now, their customer support personnel could not only see all the people on a free trial, they could see a predicted probability of converting beside their name.
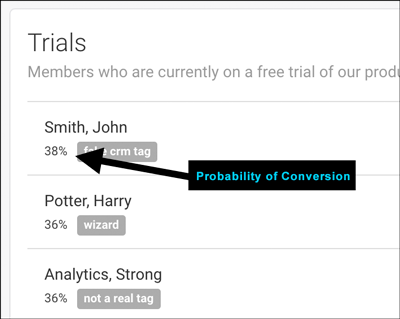
They were also now able to sort their 'free trial leads' view by the probability of conversion, targeting those high-value leads first to make sure that they weren't running into small issues that might keep them from converting. Low-value leads who simply wanted to use the free product once were at the bottom of the list, and didn't take up any of their time.
All of our work had boiled down to a single metric in a CRM. But this little metric had a huge impact on the company: they were able to downsize their customer support personnel to their previous levels, while continuing to drive their conversion rate upward to its now-stable rate of around 7.4%.
We see this not only as a big success for our client, but also a great demonstration of the important roles that data science, machine learning, and prediction can play even in relatively small businesses.

